SoK: Fully Homomorphic Encryption Compilers
@inproceedings{viand2021sok,
title={Sok: Fully homomorphic encryption compilers},
author={Viand, Alexander and Jattke, Patrick and Hithnawi, Anwar},
booktitle={2021 IEEE Symposium on Security and Privacy (SP)},
pages={1092--1108},
year={2021},
organization={IEEE},
url={https://arxiv.org/abs/2101.07078}
}Abstract
HE Compiler の調査を行う
Ⅰ. Introduction
- フィットネスのアプリでFHE Application が使われた. 医療の分野とかで有用(e.g. ゲノム)
- 機械学習の面ではロジスティック回帰, 推論
- 今後も使われていくだろう
- だが、課題も多い
- FHEプログラミングは既存のプログラムとは異なる(e.g. 条件分岐)
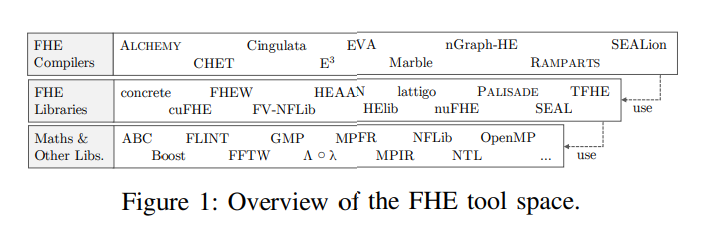
- FHE Compiler uses FHE Frameworks uses Arithmetic Library
- APIは様々だが標準化する取り組みも行われている
Ⅱ. Fully Homomorphic Encryption
-
加法準同型: ex. Paillier暗号
-
乗法準同型性: ex. RSA暗号
-
negligible: 無視できる
-
gen1: Gentry(2009)
- スカラの乗算に30minとかかかる
-
gen2: BGV, BFV, CKKS
- Leveled-FHEの登場
- CRTを使ったSIMD化
- 固定小数点を用いた CKKS scheme
-
gen3: GSW, CGGI(CGGI scheme)
- batchingを捨てブートストラップの高速化
-
FHE and MPC
- FHEは多くは2partyMPCで回路は秘匿されない
- multi party or multi keyに拡張可能 -> MultiKey_FHE
-
しかし、FHEを用いたappの開発は, 複雑なため、専門家でないと難しい
-
各方式は新しい設定と性能のトレードオフを提示し, 最先端の結果を得るには基礎となるschemeに精通する必要がある
-
データ非依存なプログラムが必要なだけでなく, 効率的なソリューションには複雑なベクトル化アプローチが頻繁に必要となるため、FHEは根本的に異なるプログラミングパラダイムを課している
-
この10年間で、最適化手法やベストプラクティスに関する膨大な知識が、FHEコミュニティで蓄積されました
- しかし、これらの技術や洞察は、しばしば文献に散見されるか、あるいは、一時的に言及されるに過ぎません
- その結果、最先端の性能結果と、専門家でない人が自分で達成できることの間に、大きな隔たりが生じている
-
開発者が今日直面している主要な工学的課題の概要を説明
-
アクセシビリティの問題が、FHEをより広く採用するための主要な障害であると認識し始めている
-
最近の研究では, より高レベルのインターフェース, より優れた抽象化, 自動最適化などを提案することでこれらの課題に対処しようとしてる
Ⅲ. What makes developing FHE applications challenging?
A. Parameter Selection
- 多くのschemeで効率的なparam選択をするのは困難
- 公開鍵暗号 ではあるインスタンスを標準化することで回避している(ex. 特定の 楕円曲線 を選択する)
- FHEでは計算によりパラメータ選択を変えるのであるパラメータセットを標準化出来ない
- パラメータ大きくするとLWE問題が簡単になってしまうので打ち消すために空間の次元(=多項式の次元)を大きくする
- 標準化は安全性の推定を提供しようとしている
- が, パラメータ選択は依存として課題
- 多項式次数 に対して opsの時間は係数 に比例
- が小さいほど安全性も高くなる
- 最小の を効率的に計算するのは未解決
- 色々なschemeでノイズ増加の公式が存在するがworst caseは保守的過ぎて実験的な値の数倍になってしまう
- 平文空間の係数 は入力値に依存, これも保守的になってしまう
- のでよく採られている方法は正しく復号出来なくなるまで徐々に を減らしてその後経験的なマージンを加える
- が小さいほど安全性も高くなる
- 多項式次数 に対して opsの時間は係数 に比例
B. Encoding
- AES, TLS とかでは平文空間を考慮する必要は無い
- バイナリにserialize出来るのでパディングだけ考えていれば良い
- ex. BGV scheme はAES-FHE暗号化, 有限体
- 平文空間が なら扱いやすいが算術演算(加算, 乗算)をするのでさえ, Sklansky Adder, Kogge-Stone Adder を使うので辛い
- エンコーディングの工夫はありそう
- ex. n-GraphHE はmultが必要ない場合、CKKSメッセージ空間の虚数部も使用し、スループットをおよそ2倍に
C. Data-Independent Computation
- 普通のプログラミングは何らかの形でデータ依存している
- ex.
if/else,loop - FHEはプライバシーの問題上そうは出来ない
- ので「回路」として概念化される事が多い
if/elseは両分岐を評価してmuxすることで可能- ループも同じやり方で出来るが厳しい
- この回路はチューリング完全でなく多項式の計算に限定される
- が, NNとか多くのappは非常によく近似できる
- ex. ゲノム配列解析の標準的なアルゴリズムは多項式近似に適していないが代替的なアプローチが存在する
- ので「回路」として概念化される事が多い
- ex.
D. SIMD Batching
- ブレークスルー: batching, packing
- 今のschemeは例え入力が1値でも常にSIMDされている
- SIMDで早くするには新しいSIMD化アルゴリズムが必要
- ex. Algorithms in HElib 行列の対角線をベクトルにすると行列-ベクトル積を効率的に計算できる
- 最も重要な最適化となる事が多い
- FHE schemeのパフォーマンストレードオフに深い理解が必要
- 機械学習とかでは元々ベクトル化されている為自動変換しやすい
- が一般的なappでは未解決
E. Ciphertext Mainteance
- 殆どのschemeでノイズの管理をする操作が必要
- relinealiarize
- modswitch
- rescaling
- bootstrap
- 明示的に呼ばなければ行けない
- ex. 乗算の直後にrelinearize呼びたいがそれは最適ではない
- ex. 計算結果に対してrelinearizeするのは無駄
- rescalingも同じ問題
- ex. 乗算の直後にrelinearize呼びたいがそれは最適ではない
- CGGI scheme は演算にbootstrapが依存しているので考慮しなくて良い
Ⅳ. Survey methodology
- FHEライブラリ, コンパイラを調査
- BFV scheme, BGV scheme, CKKS scheme, GSW scheme baseを対象
- 実際にapp実装して評価
- リスクスコア計算: 比較演算必要
- 2乗検定: 整数多項式に単純化
- 機械学習
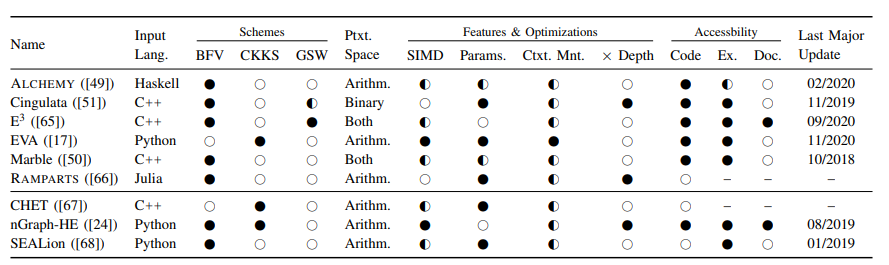
Ⅴ. FHE Libraries

Ⅵ. FHE Compilers
D. EVA & CHET(2019)
- 適切な演算の間に linearize, rescaling演算を挿入する
- mult depth を浅くする変換はしていない
- CHET: 行列-ベクトル演算の最適化に重点を置いた先行研究を包含している
G. nGraph-HE(2019)
- nGraph-HE
- IntelのnGraph MLコンパイラに基づいている
- SEALライブラリを用いて標準TensorFlow計算をBFVまたはCKKSの算術回路に翻訳する
- FHE特有の最適化
- 定数折りたたみ
- SIMDパッキング
- 遅延リスケーリング
- 深度考慮エンコーディング
- ランタイム最適化
- 特殊平文値のバイパス
を適用し、暗号入力に対する事前学習済みモデルでの推論を可能にするものである。
ただし、リスケーリング演算はナイーブに挿入され、ユーザがパラメータを定義する必要がある。
その後の研究 nGraph-HE2 A High-Throughput Framework for Neural Network Inference on Encrypted Data で、nGraph-HEは非多項式活性化関数をサポートするよう拡張
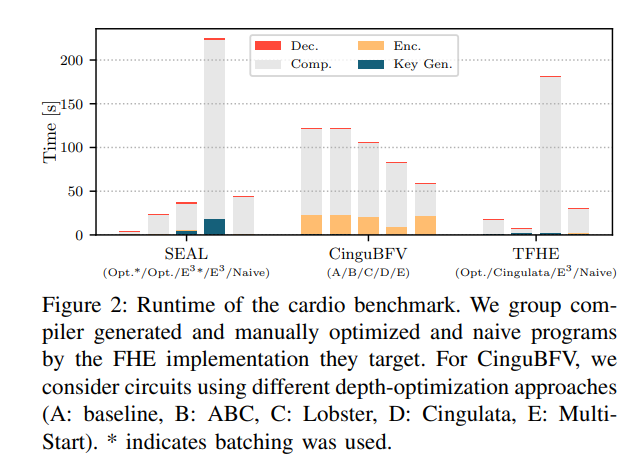
Ⅶ. Experimental evaluation