HECO: Automatic Code Optimizations for Efficient Fully Homomorphic Encryption
Abstract
Introduction
e2e architecture:
- Program Transformation
- Circuit Optimization
- Cryptographic Optimization
Most existing tools focus on the second, some extent third
- をやったのが新規性
Automated Mapping to Efficient FHE
HECOは, loop やベクトルの要素にアクセスして操作などの通常のプログラミングを出来る
-> それをSIMDに変換
naiveな実装に比べて最大3500倍高速に
- HECOは MLIR の上に構築されている
2. Background
2.1 Fully Homomorphic Encryption
2.2 FHE Schemes
2.3 FHE Programming Paradigm
Restricted Set of Operations
- binary型FHEは任意の計算が可能だが性能は劣る
- arithmetic型FHEは多項式関数しか計算できない
- セキュリティの関係で分岐が出来ない -> 両方評価する必要がある
- 状態が爆発して非効率?
最近は
- 異なるschemeに変換する研究 CHIMERA
- 非多項式関数を近似する Programmable Bootstrap
があるが, 十分実用的ではない
SIMD Parallelism
- 効率化のため, バッチに対しての演算をするように変換しなければならない為殆ど原型を留めない変形をしなければならない
2.4 Security
- FHEは integrity を持たない
- -> サーバーは別の計算を行うかもしれないし, 計算をしないかもしれない
- ゼロ知識証明 とかは integrity を保証するための技術
- 回路に対するプライバシーは無い: Circuit Privacy の話
- ckks に存在する軽微な問題
3. End-to-End FHE Compiler Design
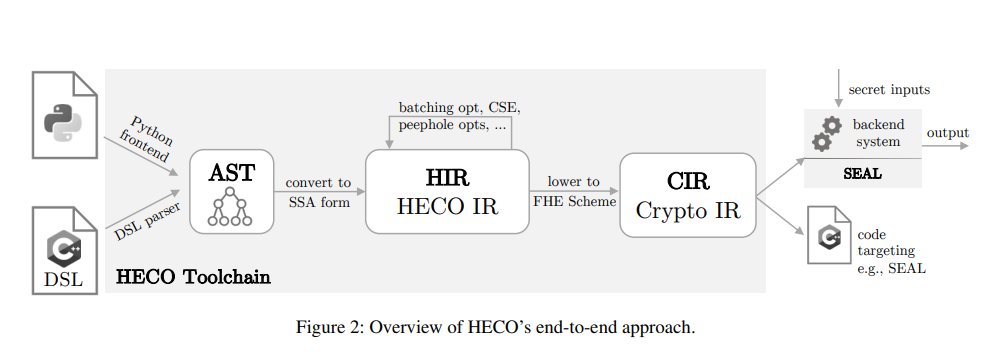
3.1 System Overview
言語フロントエンド -> AST -> HIR -> CIR -> FHE ops
3.2 Front End & High-Level IR
- Python likeなフロントエンド言語
- 低級な操作(e.g. 回転, 暗号文に対する演算) は組み込み関数で
- 他のFHE Compilerは回路を一つの式として表現するが, HECOはASTにする
- SSA への変換とかを共通処理で出来る. (わかる)
3.3 Transformation & Optimization
- MLIR を用いて段階的に Lowering
- 最適化のための, 回路よりも高レベルなSSA baseな中間表現が欲しかった
- 回路レベルではあまり効率化できない
- 最適化Passはモジュール化されているため, ユーザーが指定する事もできるし, 新しい最適化技術が出ても拡張できる(わかる)
- 最適化のための, 回路よりも高レベルなSSA baseな中間表現が欲しかった
Program Transformations
- 最新の回路最適化でも最大2x しか高速化出来ない
- 上手くマップされた実装と単純な実装の処理速度の差は数桁になることも
- SoK
- SIMDをどれだくうまくするかが劇的な性能改善に繋がる(同意)
Circuit Optimizations
演算にFHE固有の処理(e.g. Rescaling)を入れ, FHE特有の最適化. 本論文の焦点からは外れるのでskip
Cryptographic Optimizations
- FHE Schemeに焦点を当てた最適化 -> 暗号パラメータの最適化
- 現在のソフトウェア実装ではFHE演算を最小の演算単位としているが, Ring演算をするHWが出たらもっと低レベルになるのでさらに最適化の余地がある
3.4 Code Generation & Back-end
- 一般モードとexpertモードがあり, exportモードはFHEライブラリの出力コードを修正出来る
- 新しいコンパイラターゲットが出ても対応できる
4. Automatic SIMD Batching
- FHEのSIMD幅は ~ 位で有効利用すると高速化
4.1 Approach
- 高度合成のようなアプローチは遅く数十分かかったりする
- -> 効率的な局所変換を組み合わせると高速(秒単位)に(コンパイラの最適化Passの考え方)
- 従来のSLP vectorize(SLP: Synthesis Logic Planning) とは違う
- 【CEDEC 2020 フォローアップ】 マルチプラットフォーム環境で実現するLLVM ClangによるSIMD自動ベクトル最適化 | Cygames Engineers’ Blog
- 効率的なscatter/gather演算は無く, スカラ単体では扱えないので
- 汎用的に適用できる変換である必要がある
- 計算の一部をクライアントに移すといったことはしない
- vector1 elementsに最適化の焦点を絞る(??)
Strawman Approach
- naiveな演算をそのままFHE opで再現しても大きなオーバーヘッドがかかるだけ: 演算したくない要素をマスクして云々
HECO’s Approach
- 要素に対する演算を取り除くような目的の最適化をする
- ベクトル全体に作用する演算に置き換え, 一貫性を保持するための仮想的な演算を挿入して最適化をする
Notations & Conventions
- ベクトル型暗号文 (添字 )
- スカラーは先頭要素に入っているとする
%0 = extract(x, i)
%1 = extract(y, i)
%2 = add(%0, %1)
のようなSSA IRの代わりに, x[i] + y[i] と書く (わかりやすさのため).
4.2 Processing
-
最適化の前に前処理をする
-
単純化
-
正規形への変換
Vectorizeing Plaintexts
- Cipher-Plain 演算は Cipher-Cipher演算より効率的なのでなるべく利用する
- FHEアルゴリズムは効率化のためにデータレイアウトを工夫することがある
- e.g. 行列-ベクトル積では行列を diagonal vectorでグループ化すると大幅に高速化
- 平文は自由にデータのレイアウトを変更できるのでよい
e.g.
平文を として z[i] = x[i] + a, z[j] = x[j] + b の時 p[i] = a, p[j] = b とすることで1つの演算にまとめられる.
Merging Arithmetic Operations
- 演算を展開する
- e.g.
x = a + b; y = x + c->y = a + b + c- 総和のような fold styleの演算では有効になる
- e.g.
for i in 0..10:
sum = sum + x[i]
4.3 SIMD-ification
- 仮想的な insert/extract 演算を挿入し, 残ったものが翻訳される
- ex.
tensor<secret<T>>はbatchedsecret<T>に変換される
Translation Approach
- この最適化パスは全ての算術演算を線形にwalkする, 各演算について
- オペランドをSIMD演算に適した形に変換し
- 実際のSIMD演算を行い
- 結果がスカラーを期待される状況(まだ変換されていない後の演算での使用を含む)でも有効であることを確認
e.g. 要素和
for i in 0..10:
z[i] = x[i] + y[i]を考えると,
-
スカラーの演算なので
x[i]をx[0]に持ってきて足すみたいなことをする(naive get_index)- 各反復で異なる量の回転をする
- 異なる演算なので一つのSIMD演算にまとめる方法はない
- 各反復で異なる量の回転をする
-
HECOではSIMD演算を回転せずに行う
- 足した後に回転する
-
各反復で回転せずに足すので同じ演算である加算をしている
- CSE すれば単一のSIMD演算になる
-
まだ, 足した後の回転は残っている
Operand Mapping
異なる位置の演算では 回転して合わせる必要がある
e.g. x[i] + y[j]
回転量が同じだったらまとめられる(それはそう)
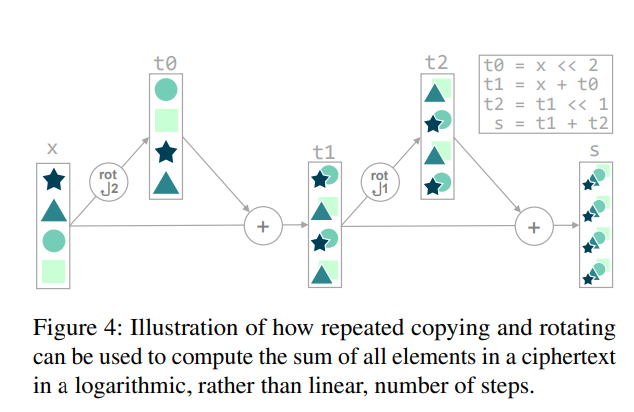
Realizing Fold Patterns Efficiently
- “fold pattern” (e.g.
for i in 0..10: sum += x) に変換を適用すると の回転が必要に- 減らすためには折りたたみを繰り返して に
5. Implementation
- 15k loc C++, 2k loc Python, Microsoft SEAL
6. Evaluation
6.1 Evaluation Setup
- Baseline実装: naive実装, optimizationしない
- Synthesis実装: ソルバで全ての可能なプログラムを探索する
- Porcupine のやりかた
Applications
-
benchmark は Porcupine によって考案された
- extended version に擬似コードある
- IEEEなので見れなかった
- extended version に擬似コードある
-
no inter-element dependencies
- ex. 線形方程式
-
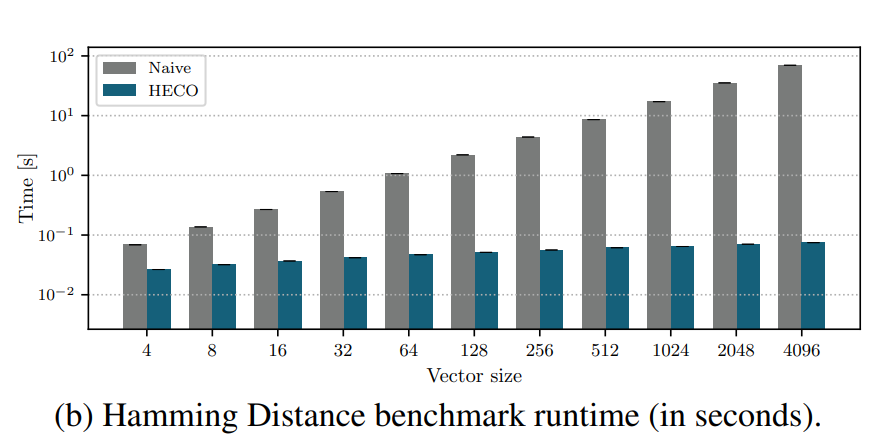
simple accumulator patterns
- ハミング距離()
- に対して
NEQ(a,b)=XOR(a,b)=
- に対して
- L2距離()
- ハミング距離()
-
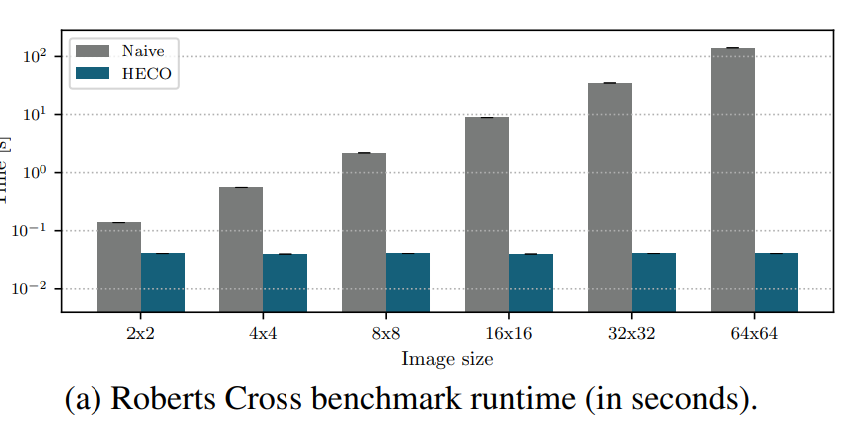
complex dependencies across a multitude defferent vector elements
- ex. (平方根なし) Roberts cross - Wikipedia
-
64x64ピクセルの画像を表す長さ4096のベクトル
6.2 HECO’s Performance
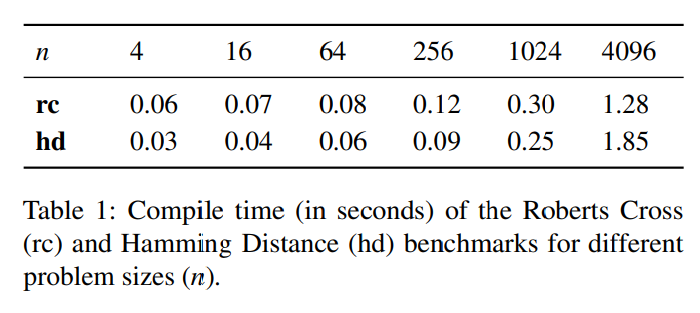
7. Related work
- FHE Compilation
- EVA: insert ciphertext maintenance operation
- EVA Improved
- Total Sum のbatching
- ours は non batching -> batching automatically
- Porcupine は最も近い
- が, 厳密に最適なプログラムを求めるのが違う, 時間かかる
- sketch求められるので敷居高く
- tools
- Armadillo A Compilation Chain for Privacy Preserving Applications
- E3
- Google’s FHE Transpiler
- は bin circuitにトランスパイル -> が実用に耐えないほど遅い
- DSL compiler
思ったこと
- 今まで見た論文の中で自分のThesisに一番近い
- というか中間発表で言ったことと全く同じまである
- 研究テーマとして存在していいんだという許しを得られた気分