強化学習入門
動機
PDFを見つけた, 強化学習 を知りたい
- 実装しないで理解したとは言えない. 理論と実装は表裏一体
- なので擬似コードを付けた. 擬似コードは素晴らしい
- 2017までのアルゴリズム
概要
- 強化学習は教師あり学習と教師なし学習の中間のようなもの
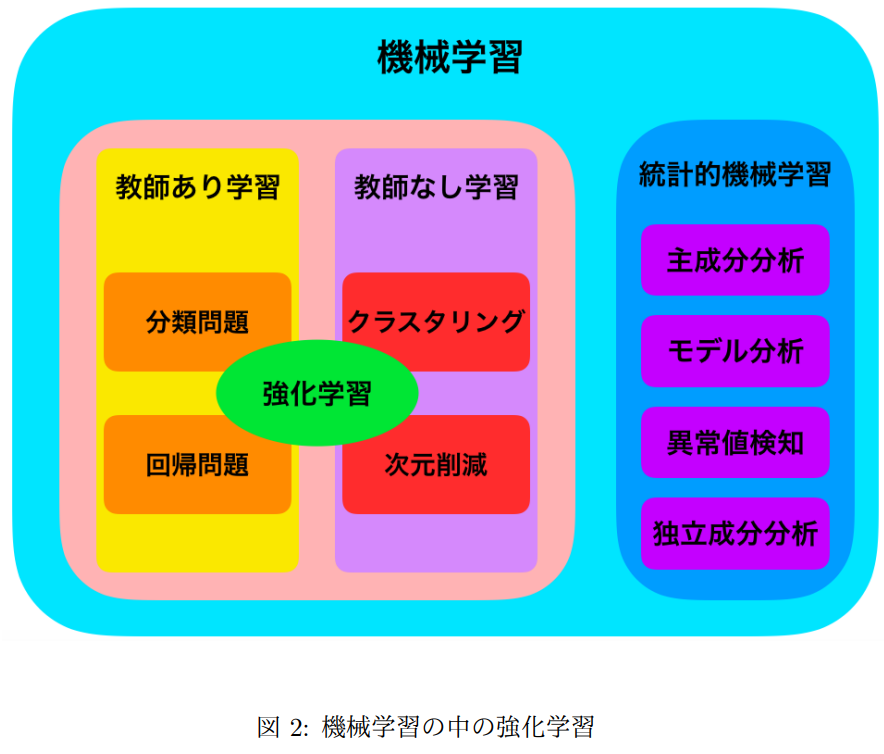
- 生物学との結びつき
- 行動戦略の買得
- 群強化学習を用いた複数の生物モデルの迷路学習
- ex. アリが餌のありかを情報伝達する
定義
簡単のため離散時間を想定
-
: 状態空間
-
: 行動空間
-
: 時刻 での環境
-
: 時刻 での選択した行動
-
: 状態 における方策=行動選択の確率
-
: 行動 によって得られた報酬
-
: 方策 で状態 における価値
-
: 方策 で状態 において, 行動 の価値
-
: 論理学では含意するの意
状態空間の例: 迷路
20x20の迷路を考えると各マスは上下左右のうち1-3個壁がある or ないで16-2通り, 状態空間は
行動は上下左右選べるので
- 状態行動価値は状態と行動の2次元のテーブル Q-table とすることも多い
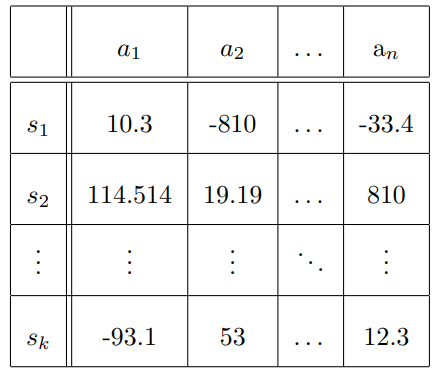
狙っている(適当な数字のプレースホルダーとして便利).
ベルマン方程式
ベルマン方程式: 強化学習の基本公式. 報酬を無限時間まで足し合わせると発散するので時刻に応じた係数(割引率) をかける.
価値とはその時刻以降で得られうる報酬の合計の期待値.
各行動での期待報酬を方策を重みとしてかけ, 足したもの
状態遷移確率 を用いて, 漸化式にできて
状態 で行動 をとった時の価値 = E(その行動の報酬 + 次状態で方策に従った行動の価値の和).
これの特殊な場合, 最適な方策 で行った時を考える.
- 最適な方策は迷いがないのである行動をとる確率が1でそれ以外が0 = 行動が決定的
- を に置き換えられる
- 動的計画法: 各時刻で最適行動を決定していく手法
- 部分構造最適性(Optimal Substructure): ある問題を小さな問題に分割出来ること
3.6 モンテカルロ法
- 現実的には状態遷移確率がわかっているケースは多くない
- わかっている: モデルベース
- わかっていない: モデルフリー
- わからない時はたくさん試行して近似的な確率分布を得る
- -> モンテカルロ法
回のうち 回目の学習中, 状態列 に対して報酬列 を観測したとき,
- 初回訪問モンテカルロ法
- 状態 が初めて出たなら収益を
とする.
- 状態 が初めて出たなら収益を
- 逐一訪問モンテカルロ法
- 任意の時刻 で収益 を導き, を評価
- モデルフリーだと期待値が計算出来ないので状態価値 がわかっても行動が決定できない
- 状態行動価値 を計算してそれが最大のを選ぶとする
- -> タプル が実際に観測されないと計算できない
- 開始点探査(Exploring Starts)の仮定: モンテカルロ-ES法
- 観測されない(=出る確率が0)ことはないと仮定する
- 方策オン型モンテカルロ制御
- 決定的な方策でなく確率的な方策にして, 任意のタプルで を保証する
- 確率的な方策 ex1. -greedy法
- ex2. softmax法
- 決定的な方策でなく確率的な方策にして, 任意のタプルで を保証する
- 方策オフ型モンテカルロ制御
- 開始点探査(Exploring Starts)の仮定: モンテカルロ-ES法
- -> タプル が実際に観測されないと計算できない
- 状態行動価値 を計算してそれが最大のを選ぶとする
TD学習
参考文献
- 自分が読んだ強化学習の資料達 - 下町データサイエンティストの日常
- https://github.com/komi1230/Resume/blob/master/book_reinforcement/book.pdf
- コミさん, 生物系の研究室でモデル生物の行動についての研究=機械学習していたらしい