MPI
プロセス並列フレームワーク
ハイブリッドモデル: 1コア1プロセス, プロセス内はOpenMPでスレッド並列とかする
一般的にハイブリッドモデルの方がオーバーヘッド少なくて効率いい
C言語様なAPIでウェ
MPIは標準規格なのでただの仕様書
実装がたくさんある
専用のコンパイラを使う
Single Program, Multiple Data
- 各プロセスで違うデータを読み込む
MPI実行モデル - 各プロセスがIDを持つ, プロセス間通信はMPIが行う
mpirun -p 4 ./a.out
mpiexec ./a.out # alt# include "mpi.h"
MPI_Init(int *argc, char **argv)
MPI_Finalize(void) // 忘れがちコミュニケータ
- 通信するためのプロセスのグループ
MPI_COMM_WORLDは全てのプロセスが所属するグループ- サブグループも作れる
別グループとのやり取りも出来るがちょっとややこしい
1プログラムにランク(グループ内のプロセス番号)場合分けを書くので可読性があれ
1つが落ちると全て落ちる
「相当苦労して泣きそうになりながらやった」
集団通信
コミュニケータ内の全プロセスでのメッセージ通信
- バリア同期
MPI_Barrier(MPI_Comm comm): 同期待つ - 大域データ通信
-
ブロードキャスト(
MPI_Bcast(void* buffer, int count, MPI_Datatype type, int root, MPI_Cmm comm)): 同じデータ配布, 全プロセスで実行される i → all- bufferは先頭アドレス ex.
x - ex.
MPI_Bcast(x, 4, MPI_INT, 0, MPI_COMM_WORLD) - 配列を配るとか, 各プロセスでも配列がallocされてないといけないが
- bufferは先頭アドレス ex.
-
ギャザ(
MPI_Gather): 全プロセスで実行, 回収 all → i
- ex.
MPI_Gather(x, 4, MPI_INT, y, 4, MPI_INT, 0, MPI_COMM_WORLD)- 2個目の4は各プロセスから受信される個数を表しているので16でない
- rank 1-3はy allocateしなくていい
- [rank * 4 + 0, … rank * 4 + 3] → [1, … 16]
- ex.
-
スキャタ(
MPI_Scatter): 分配 i → \A j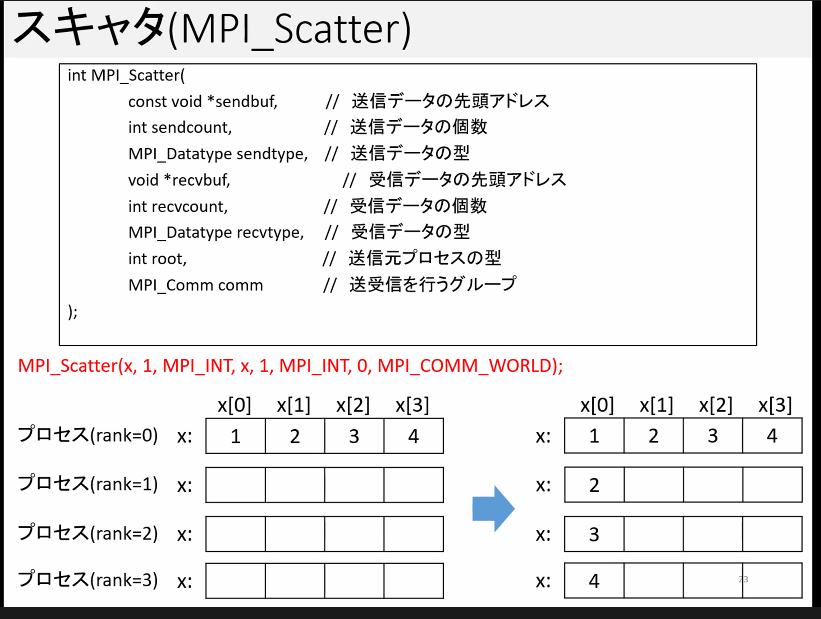
-
全交換(
MPI_Alltoall): \A i → \A j- 全てのランクに送るのでcommだけ指定する
-
- 縮約通信
MPI_Reduce(void* sendbuf, void* recvbuf, int count, MPI_Datatype type, MPI_OP op, int root, MPI_Comm comm)
1対1通信(P2P)
- プロセスのペアで通信なのでそのプロセスしか呼ばれない
- ブロックするかどうか選べる
MPI_Request*, MPI_Status*が返ってきて,MPI_Wait(MPI_Request*, MPI_Status*)で待てる
- ノンブロッキングのときは送ったデータをいじってはいけない
- データのやり取りを陽に書くのでまだ見やすい(が対応する関数を書かないと処理が進まない)
std::future 使ってほしいと思ったがあった
https://github.com/lichray/mpiex
総和:
MPI_Reduce で MPI_SUM みたいのを使うと縮約演算出来る
片方向通信
他プロセスのデータを勝手に読み書きできる
- 連続したメモリ空間を用意する
ps -ef | grep ./a.out でプロセス見れる
int * y = (rank > 0) ? 0 : calloc...
0 だけmalloc
0 はnullptrを表す
tag は被らなければ何でもいい
multiprocess行列積
行列A, BでBだけ巡回させて徐々に計算していく
Send, Recvについて
Get, Put
MPI_Win_create()
MPI_Win_fence(0, win) 準備を待つ