CUDA
Auroraはコードをデバイスに直接転送するのでメモリ転送のオーバーヘッドがない
CUDA
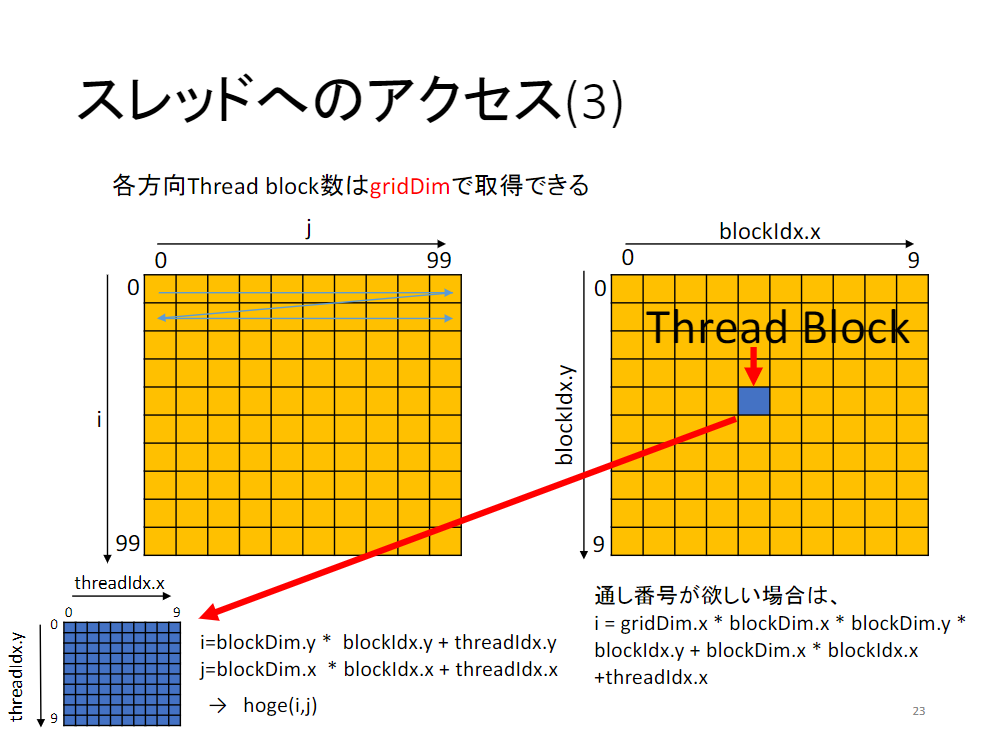
Grid x Block x Thread
max: 65535 x 65535 x 512
threadIdx: xy,blockIdx: xy: IDblockDim: xy: ブロックサイズ=何個スレッドあるかgridDim: xy: blockサイズ=何個ブロックがあるか


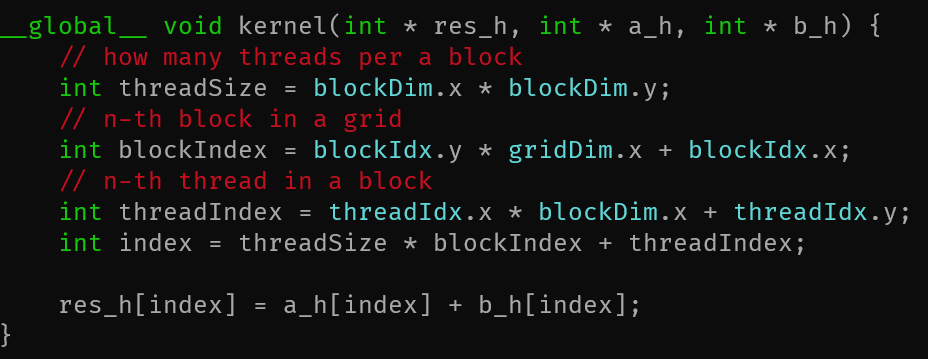
__devide__関数はデバイス側の関数で値を返せるcudaFree(void*)忘れないようにしよう- cuda化したら可読性というかロックインしてしまう
- スレッドは
Warp単位で制御- ex. 32 threads / Warp
- ex. Fermi: 16 SP/SM processorあたり16SP → 2サイクルで1Warp実行
2022-01-07
.cu で nvcc hoge.cu
- BLASS とかはやっていない