tasks
- ss3 用語理解 0.5h
- ss4 AWSベストプラクティスを理解する 4h
ss2
- AWS Well-Architected 6つの柱
- 運用上の優秀性: biz価値を提供しサポートのプロセスと手順を継続的に向上させるためのシステムを稼働/モニタリングする能力
- セキュリティ
- 信頼性
- パフォーマンス効率
- コスト最適化

-
以下の要件でのVPCの設計
- ECサイト
- appはdbに接続する必要
- dbはprivate/online
-
-> public subnetにapp, nat gateway, private subnetにdbを設置
-
選択問題は4択, 2つまで絞るのは簡単
-
複数回答: 5択, 2つ以上正解がある
- 2構成(ex. ALB, ECSやAPI Gateway, Lambda)で要件とマッチするかを考える
ss3
3-1 クラウドの用語
- アカウント: 請求される契約の主体
- エッジロケーション: CloudFront
- 3rd partyツール: 選択肢に出てきたら大抵誤り
- シャード: インデックスを分け複数ノードに分散
- スケーリング
- スケールアウト/イン: 台数、水平スケーリング
- 弾力性がある
- スケールアップ/ダウン: 性能、垂直スケーリング
- コスパ/可用性高くないので大抵不正解
- バージョニング
- S3では同じバケットで複数オブジェクトのバージョンをもたせれる
- スケールアウト/イン: 台数、水平スケーリング
- ピアリング
- 2つのVPC間で private なトラフィックを可能にする接続
- フルマネージド: 運用負担とリスクの削減が可能
- プロビジョニング: 必要なリソースを予測して準備すること
- プロプライエタリ: <-> オープンソース
- ヘルスチェック: ELB等で実施
- リージョン: 最低 2AZ/リージョン
- レガシー: クラウドのオープン技術上で動作しないappという文脈
- ワークロード: 実行状態にあるソフトウェアの全体
- DR(Disaster Recovery): 自然災害で被害を受けたときに軽減, 回復
- NAT: private IP -> global IP
- RPO(Recovery Point Objective): 目標復旧地点(過去のどの時点まで遡ることを許容するか)
- RTO(Recovery Time Objective): 目標復旧時間
3-2 要件について出題が予想される用語
- 運用上の優秀性
- 管理作業の量を最小限 -> マネージドサービス
- メンテナンス量を抑える -> 自動化/マネージドサービス
- アプリケーションコードの修正を避ける -> DBエンジンを変えない
- オーケストレーション: オペレーションやプロセスの自動化
- セキュリティ
- 信頼性
- 高可用性 -> multi AZ/クロスリージョン
- 停止しても停止時間を最小化
- NOTE: fault toleranceとは異なる
- fault tolerance: 障害時サービスを停止したりperf落とさない
- 単一障害点の除去
- 高可用性 -> multi AZ/クロスリージョン
- パフォーマンス効率
- 拡張性: 大きな変更/影響せずに機能追加/性能向上
- 一貫性: トランザクション, RDBで実施
- 結果整合性: NoSQL, read性能を最大化できる
- DynamoDBでは2/3がwriteできたらread出来る -> 古いデータを読む可能性がある
- 強力な整合性: 読み込みスループットは落ちる
- コスト最適化
ss4
4-1 スケーラビリティ
13:32
- ステートレス
- inputのみでoutputが決まる -> 柔軟性があり水平スケールしやすい
- ステートフル
- EC2にsession保存するとstatefulになってしまう
- server: session
- ElastiCache or DynamoDBにセッション情報保存(Cookieより安全)
- client: Cookie
- clientで改ざん可能なので認証の用途へは避けるべき
- スティッキーセッション: 同じclientは同じinstanceに送信
- LB(ALB or CLBの機能, Cookieを利用
- ex. オンプレから移行するときにappを修正したくないとか
- ALBとECS
- ALB(L7): コンテナに接続することが多い
- パスベースルーティングとか
- 昔は CLBでappと1:1だった
- ALB(L7): コンテナに接続することが多い
- 特定時間のトラフィック予測にもとづくスケーリング
- AutoScaling
- 対象: EC2, ECS, DynamoDB, Aurora
- スケーリングプラン
- 手動: ex. バッチ処理
- ターゲットトラッキング: メトリクス値(ex. CPU ussage)を一定に保つように
- ステップ: アラームの段階を定義
- シンプル: 1つの閾値
- スケジュール: 一定期間
- AutoScaling
4-2 固定のサーバーではなく使い捨て可能なリソース
- 自動セットアップ
- ブートストラップ: 起動時にスクリプト実行(CloudFormation, OpsWorks (Chef, Puppet))
- ゴールデンイメージ: リソースのスナップショットを再起動(AMI, VM Import/Export)
- コンテナ(Beanstalk, ECS, Fargate, EKS)
- Service Auto Scaling: サービスを増減できる
-
- ASGでmulti AZ EC2 instanceをECS Clusterとして作成
-
- Cluster上にECS Serviceを設定
-
- CloudWatch Alarmでメトリクスにより Task のmin, maxを選択
- -> instance の増減は AutoScalingが, Task の増減は ECS の Service Auto Scaling が実施
-
- Beanstalk で Docker 使用
- multi container: 内部で ECS Auto Scaling使用
4-3 自動化
手動と自動が混在する出題はできるだけ自動化された手法が正解
- deployment pipelineの自動化
- CodePipeline, CodeBuild, CodeDeploy
- infra の管理
- Beanstalk: web appの自動展開
- Auto Recovery: EC2 instanceの自動回復
- System Manager: OS patchを自動で適用
- Auto Scaling: capaity等の自動増減
- アラームとイベント
- Event Bridge (CloudWatch Events): イベントを元に Lambda, Kinesis stream, SNS topic 等を起動できる
- イベントソース: EC2, Auto Scaling, GuardDuty, 時刻
- ログ: AWSサービス, 顧客システムのログを監視/保存/アクセス
- WAF: Web firewall によるセキュリティの自動化が出来る
- 対象: CloudFront, ALB
- 攻撃元IPの遮断: IP一致条件(IP or rangeを最大10k件)の deny/allow list
- EC2への制限をするならALB必須
- CloudFrontで許可されたIPのみ通す, ALBでは CloudFront からのみ通す
- Event Bridge (CloudWatch Events): イベントを元に Lambda, Kinesis stream, SNS topic 等を起動できる
4-4 疎結合
-
明確に定義されたI/F
- マイクロサービス arch: API Gateway
-
抽象化されたサービスを検出する
- network 詳細がわからなくてもサービスを利用できる
- ELB, Route53
-
非同期統合
- SQS queueの中間の耐久性のあるstorage layer
- queue を subから polling
- キュータイプ
- スタンダード(デフォルト)
- スループット: ほぼ無制限
- FIFO: best effort, メッセージ回数: 複数回になる場合もある
- FIFO
- スループット: デフォルトで max 300tx/s
- 確実な順序付けや1回のみの処理が出来る
- スタンダード(デフォルト)
- SNS message配信
- push配信, pubからtopicをpush
- 一括送信出来るのでサービスを分離できる
- Kinesis
- cascade Lambda event
- Step Functions
- SWF
- SQS queueの中間の耐久性のあるstorage layer
-
ex. Lambda 実行の Event Sourcing
- イベントソース
- DynamoDB
- APIGateway
- S3
- Kinesis
- CloudWatch
- SQS
- イベントソース
-
Kinesis: ストリーミング処理
- ログ処理やログ分析
- 24h蓄積
- consumer=Kinesis Data Firehose
- ログ処理やログ分析
4-5 サーバーでなくサービスの利用
- ELBの3種類
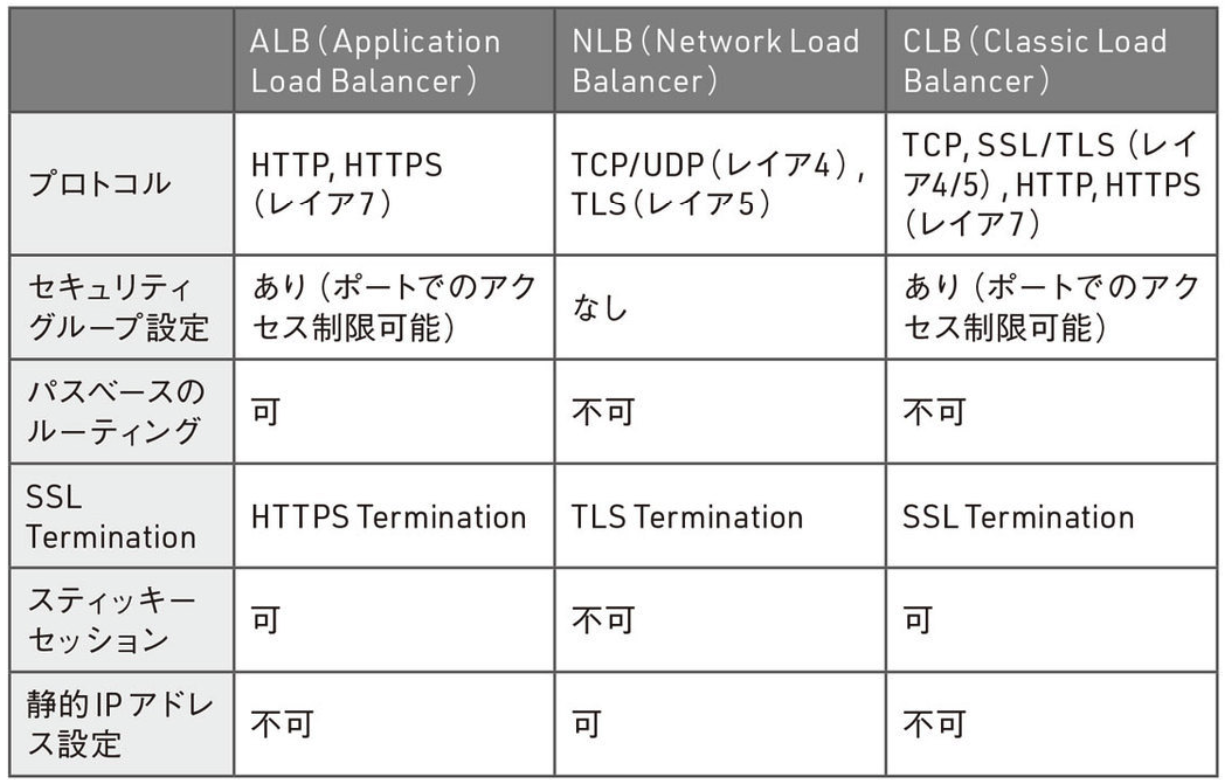
-
モバイルアプリとCognito
- Cognito Identity
- Yout User Pools (認証)
- Federated Identities (認可)
- Cognito Sync (複数デバイスで Identity を同期)
- Cognito Identity
-
SPA
- S3にstatic fileおいてCloudFront
- API Gateway, Lambda DynamoDB -> EC2より安い
4-6 DBの使い分け
- RDB
- RDS
- リードレプリカ: データ分析でトランザクション等使うときに作る; 耐久性もup
- Aurora
- 3AZに2つずつコピー
- master 1: cluster endpoint (read/write)
- read replica 3: reader endpoint (read) masterに昇格することもある
- custom endpoint: ex. 分析用
- instance endpoint: 特定のインスタンスを指す
- RDS
- DynamoDB(★)
- 3AZにレプリケーションするので耐久性
- プロビジョンスループット: readとwriteでそれぞれ設定
- キャパシティユニット: RCU/WCU
ceil(rps * (4kb: read, 1kb: write))- Auto Scalingがあるので厳密な計算不要
- プライマリキー: Partition Key, + (Sort Key)
- GSI: Partition Keyをまたいで検索するときのindex
- DynamoDB Streams: 変更履歴を24h保存
- Read結果整合性あり
- 結果整合性なし/強い整合性 順序保証, CU2倍, スループット落ちる
- オンデマンドバックアップ
- クロスリージョンレプリケーション
- pros
- 柔軟性
- スケーラビリティ
- 高性能・可用性
- データウェアハウス
- Redshift
- leaderがSQL受け取るとdisk+nodeがスケールするから性能いい
- S3に8h or 5GB updateごとにssとる, クロスリージョン可
- Redshift
4-7 単一障害点の排除
-
スタンバイ冗長化: 障害発生時にフェイルオーバー, ダウンタイムあり ex. RDS
-
アクティブ冗長化: 複数リソースに分散 ex. EC2
-
最低4instance必要なとき, 2AZ * 4 より 3AZ * 2 のほうがコスパ良い
-
DB on EC2 -> multiAZ RDS (managed, 高可用性)
-
Route53
- NAT gateway (各AZに必要)
4-8 コストの最適化
-
リソースタイプによって: インスタンスタイプ・EBSボリュームタイプ
-
弾力性: Auto Scalingにより必要に応じて・キャパシティ設定しないタイプのサービスに置き換え
-
購入オプション
- RI
- standart RI: 1y/3y
- convertible RI
- SI
- ex. データ分析・バッチ処理・バックグラウンド処理
- Saving Plan
- RI
-
EBS volume type
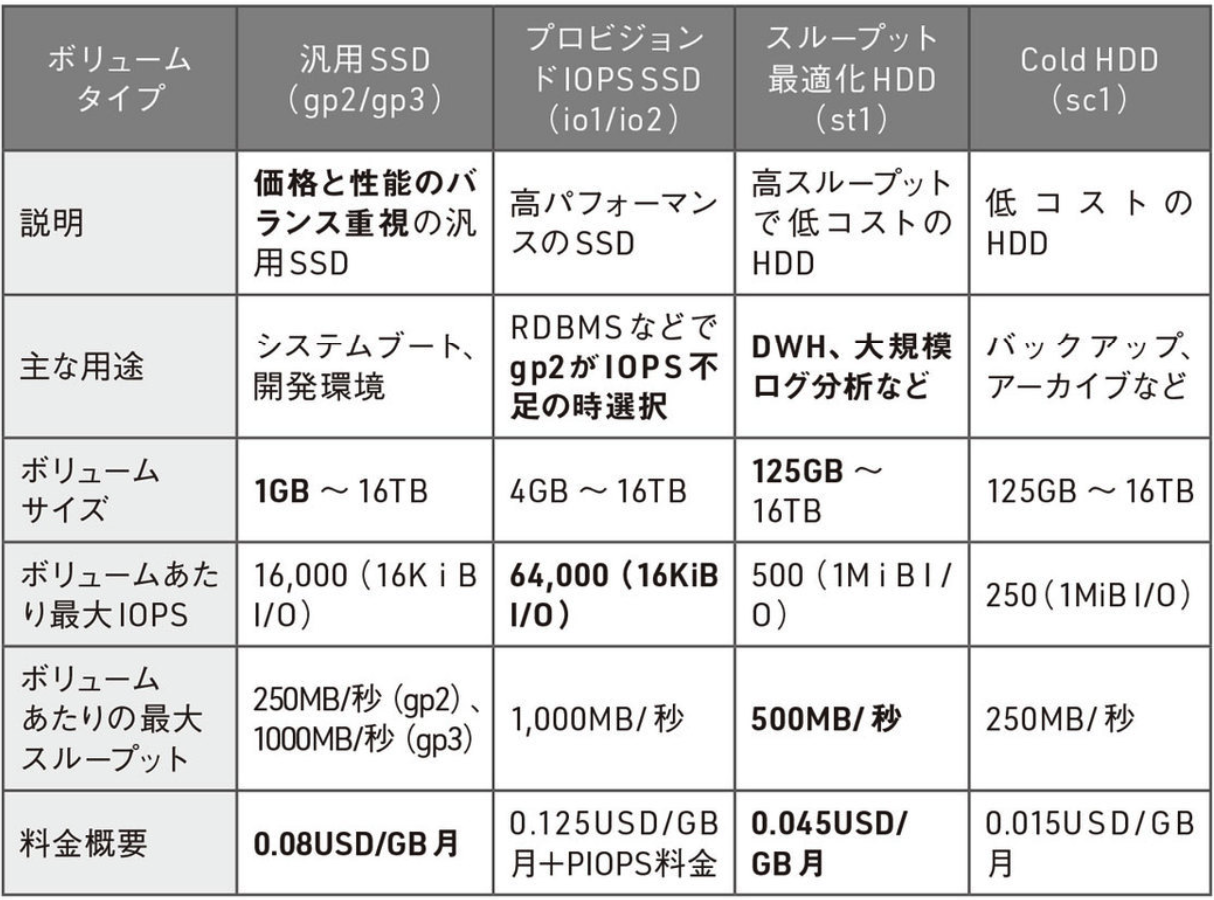
- S3 storage class
- standard (最低3AZ)
- intelligent-Tiering (最もコスト効率良いクラスに移動する, アクセスパターンわからないとき)
- standard 低頻度アクセス(IA) 頻度低いけどすぐに取り出すとき ex. バックアップ
- 1zone 低頻度アクセス 1AZのみ
- Glacier (3-5h, 5-12h, 1-5min 迅速取り出し)
- Glacier Deep Archive (取り出しに12h ~ 48h)
4-9 キャッシュの利用
- ElastiCache
- Memcached (DB cache)
- Redis (ss, レプリケーション, トランザクション, pub/sub)
- DynamoDB Accelerator (メモリ内cache)
- CloudFront (static/dynamic コンテンツをCDN)
- TTL変更可
- Lambda@Edge と組み合わせ可
- Shield (DDoS対策)
- S3 Transfer Acceleration
- 直接S3でなく、CloudFront edge locationを経由して早いbusでアップロード
4-10 セキュリティ
- public/private subnet
- ELB, NAT gateway, 踏み台サーバー -> Web/app/DBサーバー
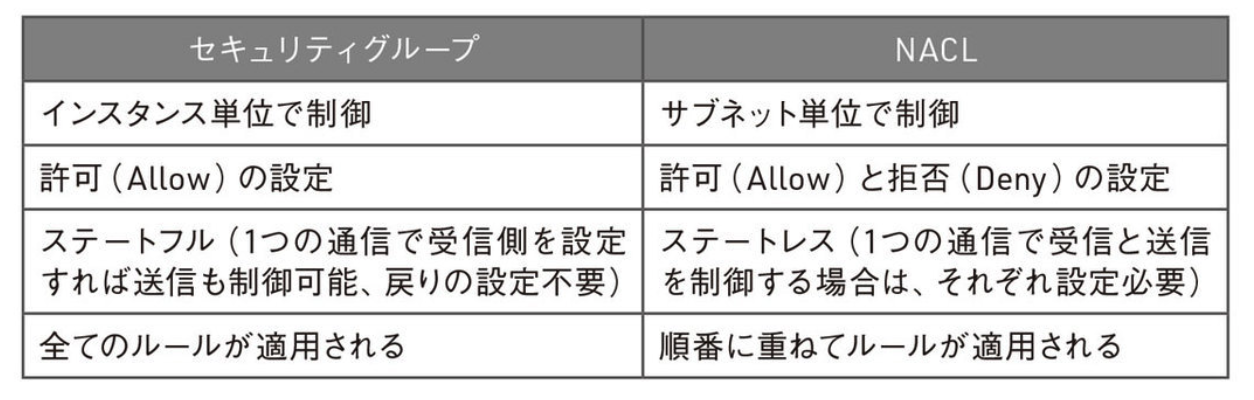
-
ex. ALBでインターネット接続に対してSG設定する
- inbound: 0.0.0.0/0 許可
- outbound: EC2 instance のlistener port
- EC2 ヘルスチェックポート outbound: instance
- EC2 instanceではALBのSGの設定からのみ受信
-
データセンター(VPC)内も暗号化必要, 2通り
- client <- https -> ALB(SSL終端) <- https -> EC2
- client <- https - NLB(httpsスルー) -> EC2
-
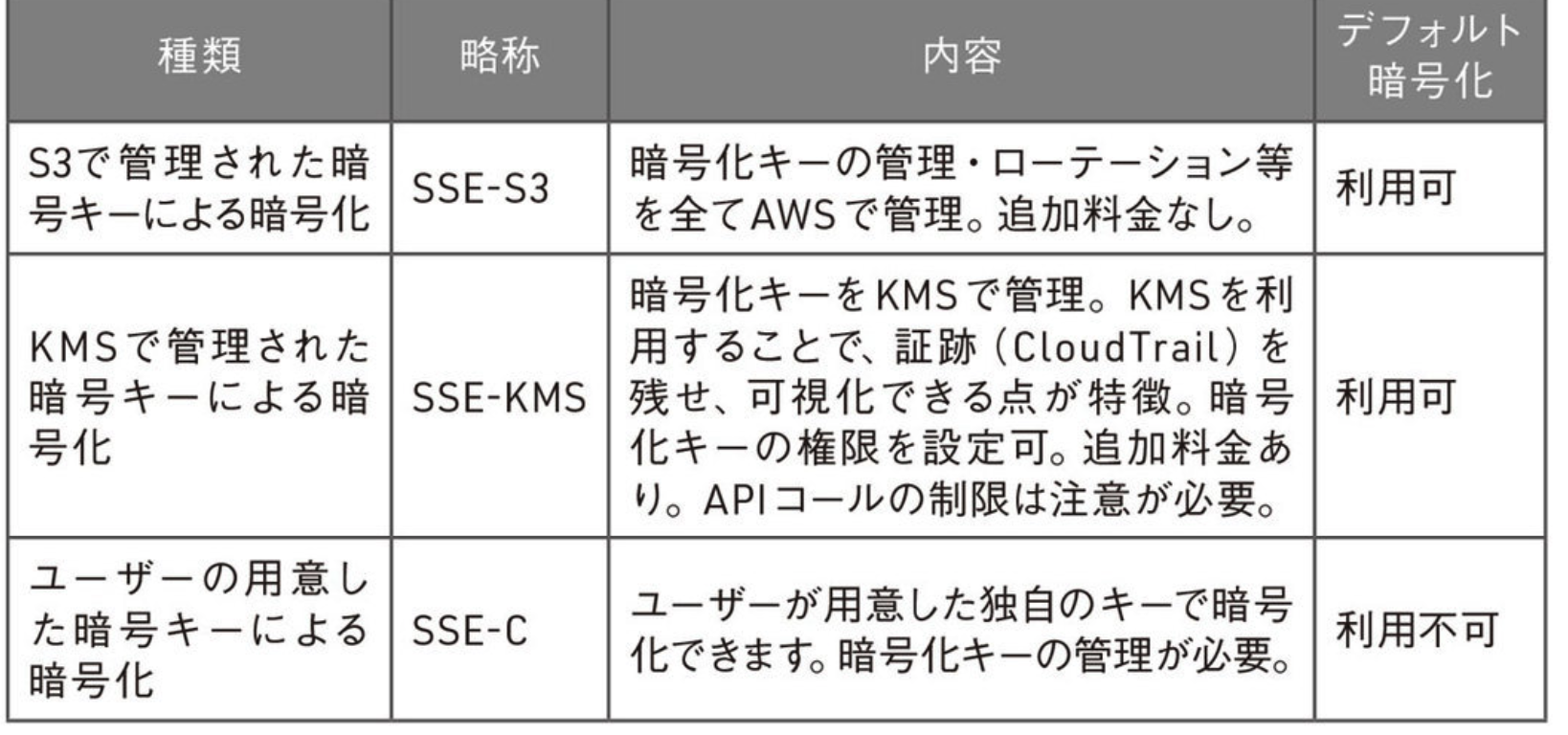
S3サーバーサイド暗号化
- SSE-S3 (full managed, やすい) > SSE-KMS > SSE-C(keyユーザー用意) が一番大変
- ロギング
- CloudTrail log: アクティビティ記録、監査用
- VPCフローログ: IP traficキャプチャ
- CloudWatch Logs: EC2 instance, CloudTrail, Route53等のログファイルの監視・保存・アクセスができる
4-11 練習問題
-
- A
-
- D
-
- C
-
- C
-
- B
-
- A
-
- A
-
BC
- push配信 pub/subは SNS
-
- B
-
AC
- Federated Identities (identity管理)
-
- A
-
- B
-
- A
-
- D
-
- D
-
- B
-
- D
-
DB
- reader endpointが読み取り性能を上げる
-
- B
-
AD
- 複数分散は複数値回答rouitng
-
- C
-
- B
-
- C
-
DB
- 一番安いのは standart RI
-
- A
-
- C
-
- B
-
- D
-
- B
-
- C
-
- A
-
- B
-
- D
-
- C
-
- B
-
- D
-
CD
- SGは許可の設定ができるのが特徴
-
- A
-
- C
-
- B
5 セキュアなアーキテクチャの設計についてのベストプラクティス
9:08-11:45
- 5-1 ALB アクセスログ
- (NLBも HTTPreqでないけどできる) - 5-2 VPC
- subnetのroot tableでinternet gateway (0.0.0.0/0) を指す
- subnetのinstanceにglobally uniqueなIPアドレスがある
- 5-3 VPC
- networkACLはstatelessなので着信と送信を定義する
- 0.0.0.0/0 -> 443
- web server -> 3306(MySQL)
- networkACLはstatelessなので着信と送信を定義する
- 5-4 VPC pairing でpublic IPなしで通信できる
- CIDR blockが一致・重複する接続や推移的な接続はできない
- 5-5 Redshift
- Redshift拡張VPC routing: S3とRedshiftをprivateに接続
- 5-6 IAM
- LambdaからDynamoDBの操作もIAM role
- 5-7 IAM
- AWS resourceのアクセス許可もIAM role
- 5-8 IAM
- クロスアカウントIAMロール(3rd accountに許可できる=監査)
- 5-9 Config
- AWSリソースの構成変更をチェックできる
- 5-10 RDS
- DB作成時にデータ暗号化を選択出来る
- 通信の暗号化の要件もある
- DB作成時にデータ暗号化を選択出来る
- 5-11 AWS WAF
- XSS
- 5-12 Secrets Manager
- RDS, Redshift, DocDBでsecretのrotationが出来る
- 5-13 KMS
- 使用ログの可視化出来るので監査対応可能
- 5-14 CloudTrail
- ログはデフォルトで暗号化されている(SSE-S3)
- KMSのキーも選択可能
- S3 lifecycleに従い自動アーカイブ・削除可能
- 5-15 CloudTrail
- 整合性検証機能: sha256で署名されているので偽造むり->監査
- 5-16 CloudFront
- OAI: CloudFront user
- signedURL/cookieでS3へのアクセスを制限したうえで
- OAI: CloudFront user
- 5-17 S3
- デフォルト暗号化: 保存時暗号化, DL時復号化
- 5-18 NLB
- スルーさせ, EC2を終端とする
- 5-19 2019/1 にTLS終端に出来るように
- サーバーの負荷軽減
- 5-20 ALB
- SNI(Server Name Indication): server単位からdomain単位に
- -> 複数TLS cert作れる
- -> 1つのLBで複数ドメイン使える(wildcardでなく)
- SNI(Server Name Indication): server単位からdomain単位に
- 5-21 VPC
- app in private subnet <-(VPC endpoint)-> S3, DynamoDB
- 5-22 Amazon Inspector
- EC2 instanceの脆弱性診断
- 5-23 KMS
- ログ可視化出来る -> 監査
- 5-24 IAM
- IAM policy
- Effect: Allow, Deny
- Action
- Resource
- Condition
- IAM policy
- 5-25 AWS WAF
- Geo一致条件: 国に基づいて
- IP一致で例外で許可もできる
- Geo一致条件: 国に基づいて
- 5-26 Direct ConnectとSnowball
- internet介さずに大量データをロード
- 専用線で接続/物理 storage使用
- 5-27 Kinesis Data Firehose
- ETL(抽出・変換・ロード)サービス
- 送信元はIoTデバイス, 小さなデータが大量
- 5-28 Athena
- serverless, SQLでS3データをクエリ
- 5-29 FSx For Lustre
- Linux共有ファイルシステム
- 高速でHPC向け
6 弾力性に優れたアーキテクチャの設計についてのベストプラクティス
- 6-1 EBS
- BCP(障害/自然災害)対策: EBS snapshot=別AZのS3に保存
- 6-2 Elastic Beanstalk
- 外でRDS起動してblue/green deploy
- 6-3 EC2
- Dedicated Host: ソフトウェアライセンスで物理コア数を制限されているとき
- 6-4 EC2
- placement group
- cluster: 単一AZ
- partition: 複数の論理partition
- spread: networkと電源が異なる
- placement group
- 6-5 S3
- CRR(cross region replication): 別regionにコピーして災害対策
- 6-6 Glacier
- 迅速取り出しで5分以内に取り出せる
- 6-7 DynamoDB
- DBstreamでテーブルデータの変更をキャプチャできてリアルタイムアプリ
- 6-8 RDS
- read replicaをスタンドアロンのDB instanceに昇格出来る(バックアップ)
- multi AZは同期replicationに対してread replicaは非同期
- read replicaをスタンドアロンのDB instanceに昇格出来る(バックアップ)
- 6-9 S3
- 大容量バックアップとか使える
- 6-10 Aurora
- primary DB (read/write) multiAZ
- aurora repica (read)
- 6-11 Glue
- ジョブのブックマーク: ジョブ実行の状態を保持
- 6-12 EC2
- 災害対策: 別regionにAMI作成
- 6-13 Route53
- 加重routing: blue/green deploy
- 複数値回答: すべての正常serverにランダムに分散
- 6-14 VPC
- private subnetにあるDBのpatch updateはpublic subnet に NAT gateway配置
- 6-15 Organizations
- 本番と開発用分けるとか
- OU(組織単位)作れる
- 6-16 SQS
- スパイク発生するときデータ欠落防ぐには
- DB writeの前にSQS挟む
- スタンバイDBを別AZ
- スパイク発生するときデータ欠落防ぐには
- 6-17 Snowball Edge
- 5日かかる
- Snowball + 移動車両(local storage + gpu computing)
- オンプレからの移行に使う
- Snowball Mobile: 100PB入るトレーラ
- ~数百TBならSnowball Edge Storage Optimized
- 6-18 Transit Gateway
- VPCとオンプレnetworkを接続するルーターになり簡素に
- 6-19 Storage Gateway
- オンプレから使うcloud storage
- 6-20 Shield
- Standart: 無料
- Advanced: 有料, EC2, ELBでも使える
- 6-21 CloudFront
- signed URL: ファイル毎
- IAMユーザーでもkeypair作れる
- signed Cookie
- signed URL: ファイル毎
- 6-22 CloudFront
- フィールドレベル暗号化: セキュリティレイヤを追加出来る
- 特定のdata field(?) に特定appのみがアクセス出来る
- https内で機密データを更に暗号化
- 特定のdata field(?) に特定appのみがアクセス出来る
- フィールドレベル暗号化: セキュリティレイヤを追加出来る
- 6-23 S3 VPC
- S3へのVPC endpoint作成する
- gateway型: S3, DynamoDB
- interface型(private link): たくさん
- S3へのVPC endpoint作成する
- 6-24 WAF
- WebACL: 特定の国からの攻撃防ぐ
- 6-25 Transfer Family
- FTPとか
- 6-26 Systems Manager
- 複数AWSサービスをまとめて
- Parameter Store: AMI IDとかdatabase stringとか
- 複数AWSサービスをまとめて
- 6-27 S3
- object lock
- ガバナンスモード: 許可持たないとupdate/deleteとかむり
- コンプライアンスモード: rootユーザでも保持期間とかいじれない
- object lock
- 6-28 S3
- バージョニング
- 削除しても削除マーカーがついたバージョンになる
- バージョニング
- 6-29 S3
- MFA Delete: バージョニングあっても削除したときに認証はいる
- 6-30 AMI
- LaunchPermission: 特定アカウントのみがAMI使える
- 6-31 DynamoDB
- ポイントインタイムリカバリ: 特定日時(~35day)に戻せる
- それ以上とかテーブル削除ではondemand バックアップ
- ポイントインタイムリカバリ: 特定日時(~35day)に戻せる
7 高性能アーキテクチャの設計についてのベストプラクティス
- 7-1 S3
- Storage Gateway: オンプレでストレージ不足したら
- 7-2 Route53
- DNSフェールオーバー: オンプレ死んでたらAWS
- ヘルスチェックはオンプレでも使える
- 7-3 EFS
- EC2向けのファイルストレージ
- EBSと違い複数AZに保存され、ほかからアクセスできる
- EC2向けのファイルストレージ
- 7-4 SQS
- SQS queueのサイズ -> CloudWatch -> EC2 AutoScaling
- 7-5 EBS
- io多いときはEBSはIOPSにする
- 7-6 DynamoDB
- パーティションキー全体で均一にアクセスされるように
- 7-7 AMI
- base AMI使うとサーバーのビルド時間短縮
- 7-8 Aurora
- ~100msでレプリケーション
- 7-9 Redshift データウェアハウス
- PBクラスのデータの分析
- 7-10 S3
- CORSでS3のoriginを許可すればよい
- 7-11 DynamoDB
- JSON docの保存
- 7-12 DynamodB
- ACIDないBASE(結果整合性)
- データ追加が多く修正ない処理に適している
- 7-13 CloudFront
- TTL設定できる, 動的コンテンツではTTL=0s
- 7-14 ALB
- URLパス毎にrouting出来る
- 7-15 Lambda
- 最大実行時間 15分以内に設定できる
- 7-16 Amazon FSx for Windoes
- SMBprotocolでWindowsFS実行可能
- 7-17 API Gateway
- APIcache使える(default: 300s, max: 3600)
- 7-18 EC2 instance store
- EBSと違い永続化されないが高性能
- 7-19 Global Accelerator
- 複数regionにトラフィック分散
- 7-20 DynamoDB
- ASで急なトラフィック増にも対処出来る
- 7-21 EC2
- 起動テンプレート
- human error抑えられる
- 起動テンプレート
- 7-22 SQS
- producerとconsumerを分割すると疎結合に, それぞれscale
- consumer: polling
- 7-23 CloudWatch
- 複合アラーム: ルール式とか組み合わせ、SNS topic, Systems Manager Incident Managerでincident作成出来る
- 7-24 S3
- batch operation: job作り1API reqで数十億個とか管理出来る
- 7-25 S3
- イベント通知
- 7-26 S3
- Lambda <-> RDS proxy <-> RDS
- connection pool作れるのでLambda増えても大丈夫
- Lambda <-> RDS proxy <-> RDS
- 7-27 DataSync
- オンプレとAWSでデータ移動自動化, JSONとか
8 コスト最適化アーキテクチャの設計についてのベストプラクティス
- 8-1 ECS
- Fargateだと自動スケールとかして管理楽
- 8-2 EBS
- 増分snapshotでストレージ節約
- 8-3 EC2
- 常時稼働するならRI
- 8-4 Redshift
- PITbackupで自動/手動あるが手動は自動で消えないので削除推奨
- 8-5 Organizations
- EC2とかS3利用料増えると割引があるかも
- 8-6 EBS
- 10GBとかならgp2(SSD)が最安
- HDDは125GB~ なので
- 10GBとかならgp2(SSD)が最安
- 8-7 EC2
- 落ちても良いならSI
- 8-8 S3
- あまりアクセスしないけど高可用性なら S3 standart 1A
- 8-9 EBS
- スループットほしくてコスパいいのはHDD(st1)
- 8-10 S3
- S3は受信無料、送信だけ課金
- 同じregionのEC2/CloudFrontへのデータ転送とかは無料
- 8-11 S3
- lifecycle policy設定してやすいstorageに移すようにするとコスパ良い
- 8-12 RDS
- dev環境とかはDB instance停止すると安くなる
- 8-13 S3
- 転送コストはバケット所有者でなくリクエスタが支払うことも出来る
9 実践問題
-
130min/65Q -> 1問あたり2分
- 時間は余裕ありそう、問題文の要件を漏らさず読む
-
- B,
CE
- RI はEC2の話, Fargate, Lambdaは compute SP
- B,
-
- A
-
- D
-
- B
-
- A,
DE
- 低コスト, サブドメインなので LBいらない
- A,
-
BD
- 可能な限り最高の -> 「EC2 instance store」
- 20TBでio perf高い -> EBS
-
- E, D
-
- A, E
-
- D
-
- B
-
- D
-
- A (or D) -> D
- FTPは暗号化無理
-
- C, E
- SGでIP制限 -> WAFでIP制限
-
- A
-
CD, E
- L4 なのでALB選択不可
-
- D?
-
- C,
A?E
- 最小限の運用で = Kinesis Data {Streams, Analytics} 使う
- C,
-
- C, E
-
- C (or B), D
- FargateはDynamoDBと組み合わせられない?
-
- D, A
-
- C,
AB
- エンドポイントへのroot tableエントリを作成
- C,
-
- B, C
-
- B
-
AC, B
- 送信SGは不要, Microsoft SQL server(port 1433) からの inbound
-
- D