[malloc] malloc動画(2011)メモ
malloc動画(2011)メモ
The 67th Yokohama kernel reading party - YouTube を視聴しメモする. 記事中の画像は当動画より引用.
古典的malloc(krmalloc)
K&Rで出てきた
fist fit: 空き領域を連結リストでつなげる- フラグメンテーションが進まない限り, malloc $O(1)$
- current ptrが指すのはfreeした領域
- free $O(n)$
- 拡張するかの判断にfreelistを一周しなければ行けない
- 前のptr探すのに
- キャッシュが汚れる => 性能が落ちる
現代(glibc malloc)
現在は小さいmallocが頻発 => 高速化
-
X windowsでは1ピクセル動く度に
-
変数が宣言される度に
-
最大の問題はフラグメンテーションと仮定
-
時代は
best fit -
malloc時
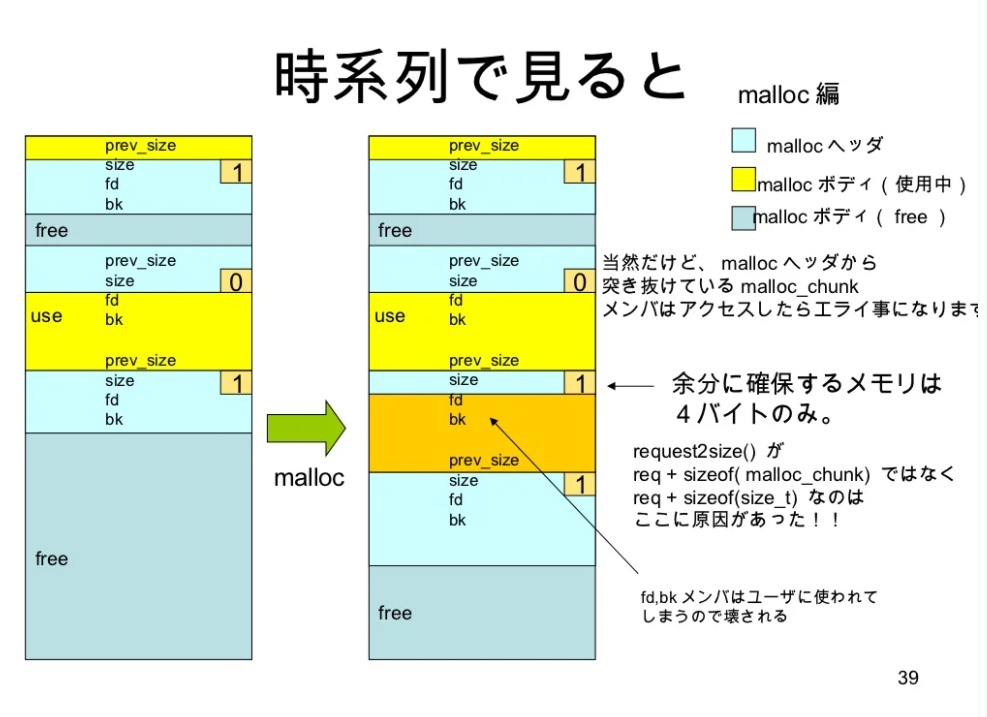
-
free時
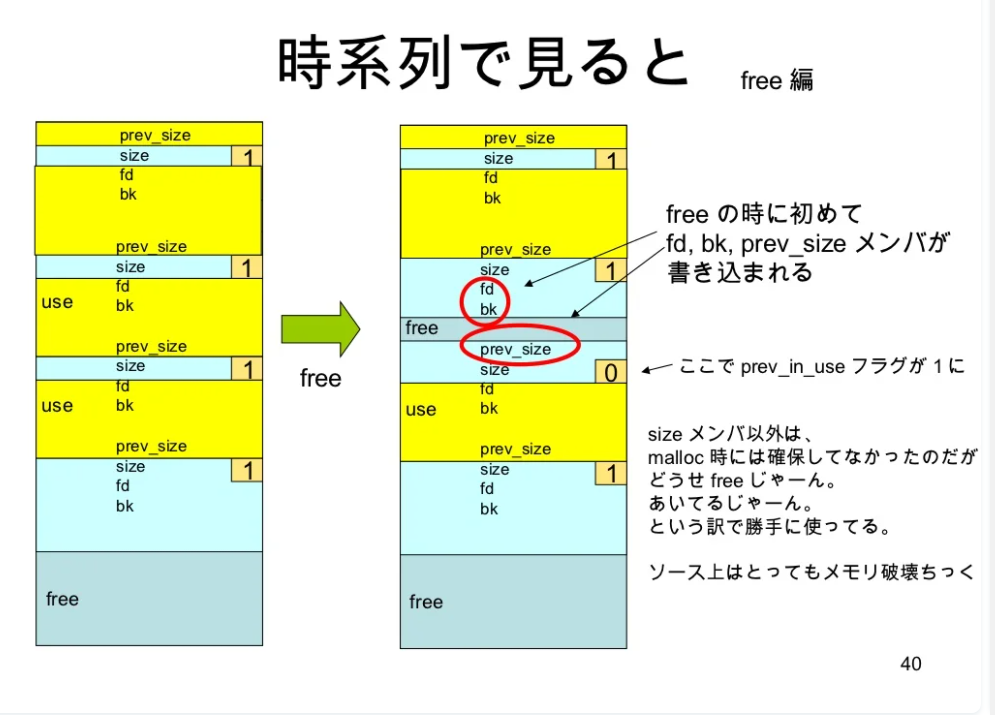
-
Just idea:サイズ順にソート -> free時に併合出来ない,余計fragmentする 構造体: 次と前へのアドレスの差, 次と前のリストのポインタ
-
32bit ptrは下位2bitは0
- glibc mallocは8の倍数で切り上げなので下位3bitは0
-
sizeメンバの下位にuseかどうかのフラグ(
PREV_IN_USED)をねじ込む -> prev_sizeいらなくなる -
userにわたす時fk, bk削るのでsizeだけ
- freeする時bk計算できなくないですか?, 進むだけでいいなら問題ないけど
- この後言ってくれるらしい
- freeする時bk計算できなくないですか?, 進むだけでいいなら問題ないけど
-
unixは10000行(xv6), mallocは20行くらい
- linuxのmalloc(glibc malloc)は5000行, multiset?考慮するので
高速化アイデア(Segregated Free List)
-
free listで1つにしなくてもいい?
- 小さいサイズ(512-byte)では8byte毎にbinを作り小さいリストに(small bins)
- 段々と間隔を開ける
- -> 画像とか扱うと数十MBとかmallocする
- heapがもう一つあればでかい時用に使える -> その為の [[mmap]]
- -> 画像とか扱うと数十MBとかmallocする
-
fdに
/dev/zero渡すとメモリ確保APIとして使える -
下から2番目bitを
IS_MMAPEDflag -
mmapはfreeするとOSに返される
-
malloc_checkってなんだ?
-
リスト管理していないのでfragmentation起きにくい
- スパコンではthresholdを0にしてmmapさせないのが定石らしい
-
freelist一周問題はサイズが大きいbinだけ探索 -> avg cost 1/2
-
K&R mallocに負ける
- 理由: freeされたばかりの領域はcacheに乗っていそうなのでそこをmallocするとcache hitしやすい, 昔はcacheとか無かった?
- malloc作りたくなる病
合併を遅延する
- すぐに繋げちゃうと前の方使う時にはcacheから落ちているので遅くなるから
bins[0], [1]は使われていない(最低:32byte)のでそこを遅延のためのリストヘッドを入れる- やめてほしい
- 一般的にはバースト状態(たくさんmalloc&free ex. 起動時), 定常状態(malloc&free交互)があり定常状態では遅延のリストが貯まらないので性能いい
スレッドセーフなmalloc
- Just idea: malloc前後で
lock(), unlock() - lock freeな世界 -> 現実的に無理
- 実行時に新しいheap(Arena)を作る
- スレッド毎に若い順に探し, 無かったら専用のArenaをmmapで作る((TLS; thread local storage on RAM)に) -> 1 arena/thread に収束, 空間効率重視
- googleのmallocは最初から1 arena/threadにしてlock freeに(=時間効率重視)
- crates.io: Rust Package Registry の命名ここから来ている?
- 分離方法: Arenaを1M alignにする
arena_ptr = ptr & ~0xfffffIS_NON_MAINARENAはsizeの下位3bit目- 課題: linuxにalignを保障するsyscall無い(winはある)
- 2M mmapして絶対1M diffな所があるのでそこをremapしてmummap
- スレッド毎に若い順に探し, 無かったら専用のArenaをmmapで作る((TLS; thread local storage on RAM)に) -> 1 arena/thread に収束, 空間効率重視
- dlmallocではlarge-binがリストからbin-treeに
- glibcでは
int_malloc()に全てが詰め込まれている,嘘コメントあった- 普通の人はmalloc読まないから
- 現在(2022)は関数分割され, コメントもわかりやすく